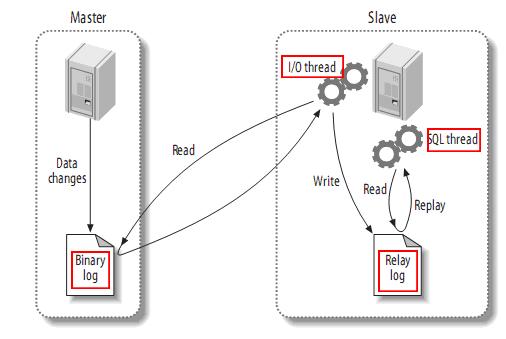
PS:从图中可以看出,Slave服务器中有一个I/O线程(I/O Thread)在不停地监听Master的二进制日志(Binary Log)是否有更新:如果没有它会睡眠等待Master产生新的日志事件;如果有新的日志事件(Log Events),则会将其拷贝至Slave服务器中的中继日志(Relay Log)。(3)Slave重做中继日志(Relay Log)中的事件,将Master上的改变反映到它自己的数据库中。
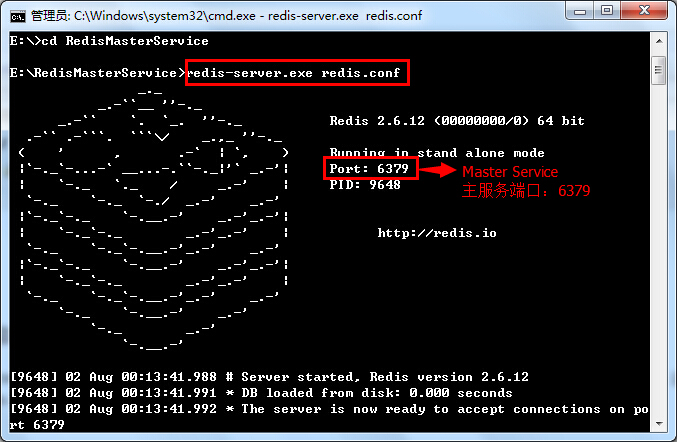
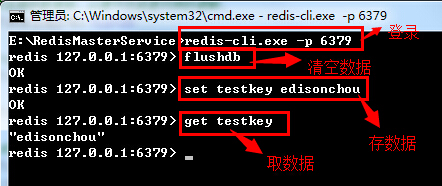
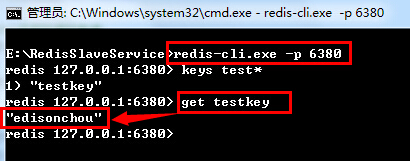
PS:从图中可以看出,Slave服务器中有一个SQL线程(SQL Thread)从中继日志读取事件,并重做其中的事件从而更新Slave的数据,使其与Master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。经过了上面的简单简介,我们初步了解了什么是主从复制,以及在关系型数据库中数据是如何复制的。在这,我们不由疑问在Redis中又是怎样实现数据复制的呢?别急,我们先来实践一下,先对主从复制得到一个感性认识,再由感性认识升到理性认识去理解一下。So,Let's start doing.
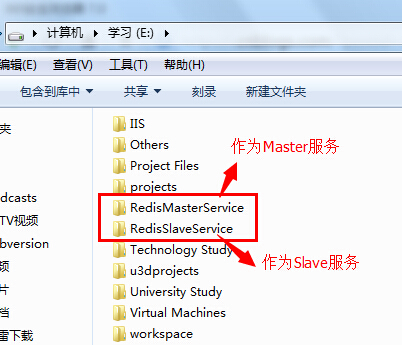

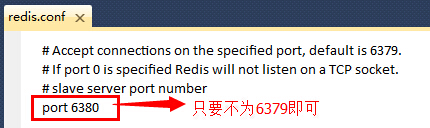
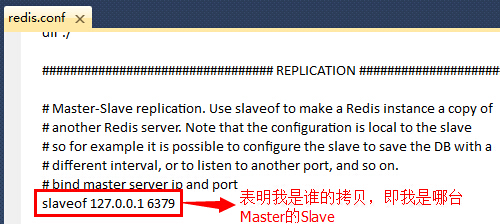
PS:建议使用类似于EditPlus、Notepad++等专业一点的编辑器打开redis.conf配置文件,这样查找和编辑都比较直观明了。如果这些你都没有,那你可以用Visual Studio打开来编辑(如果你连VS也没有,我只能呵呵了,你用记事本编辑吧,么么嗒)。好吧,我就没有EditPlus和Notepad++,重装了系统就没有装这些编辑器,被你们看穿了。(2)修改Slave服务的配置文件(redis.conf)

 [/url][/url]
[/url][/url]
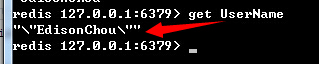

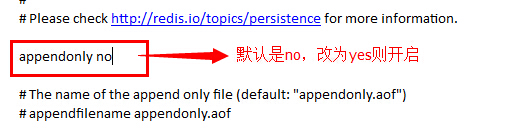
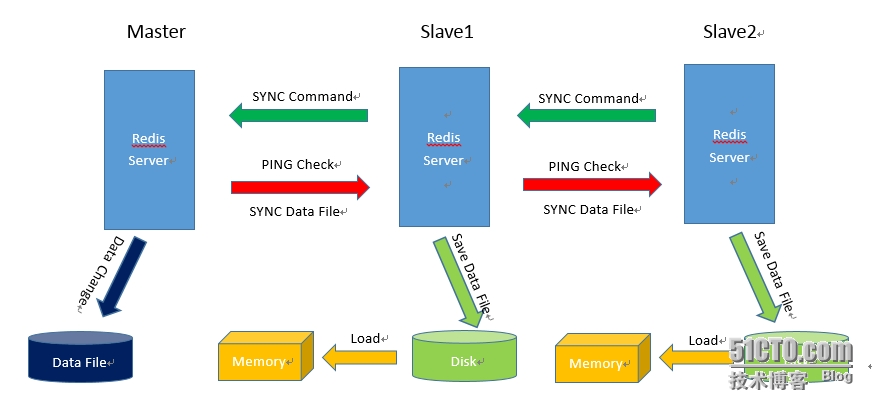
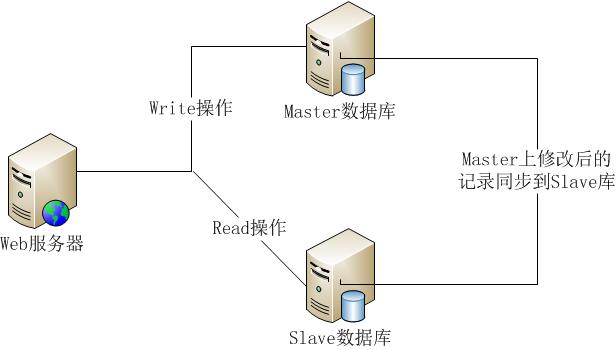
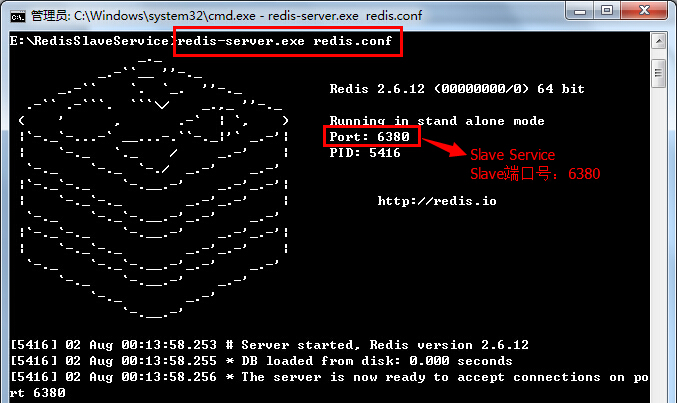
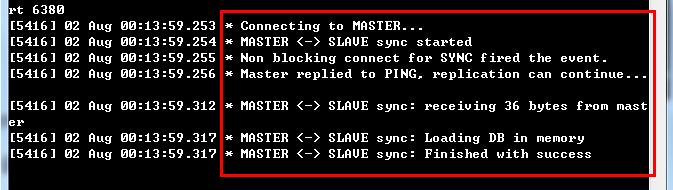
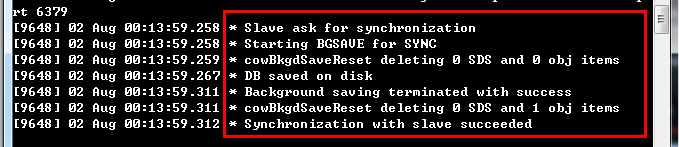
PS:不管什么原因导致Slave和Master断开重连都会重复以上过程。(3)Slave接收到Master发来的数据文件之后,会保存到本地,待接收完成后,加载到内存中,这就完成了一次数据复制。之后,Master只要一有数据更新,便会写入数据文件并发送给各个Slave,而Slave也会一直监听Master发来的更新,并重新加载,形成一个数据同步的循环。

| 欢迎光临 PHP开发笔记 (http://phpvi.com/) | Powered by Discuz! 6.1.0 |